New tutorials
Hereby some recommended new tutorials to learn programming in NetLogo. The first one is from the NetLogo team. It provides a beginner’s guide to NetLogo programming. The other tutorial is







Hereby some recommended new tutorials to learn programming in NetLogo. The first one is from the NetLogo team. It provides a beginner’s guide to NetLogo programming. The other tutorial is

A new version of the book is out in time for the Fall semester! Due to requests to have the book available on multiple types of devices, we reimplemented the
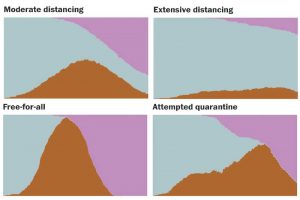
Agent-based model demonstrates how social distancing flattens the curve of corona virus cases.